Different Approaches to Machine Learning (ML)
Hello Folks, Welcome back to Learnizo Global. Machine learning techniques are required to improve the accuracy of predictive models for business logic. In our previous article, we discussed in detail the importance and basic concepts of Machine Learning. Based on the volume and type of data and depending upon the business logic to be addressed, there are different approaches to Machine Learning. In this article, we will discuss in detail the different approaches to Machine learning.
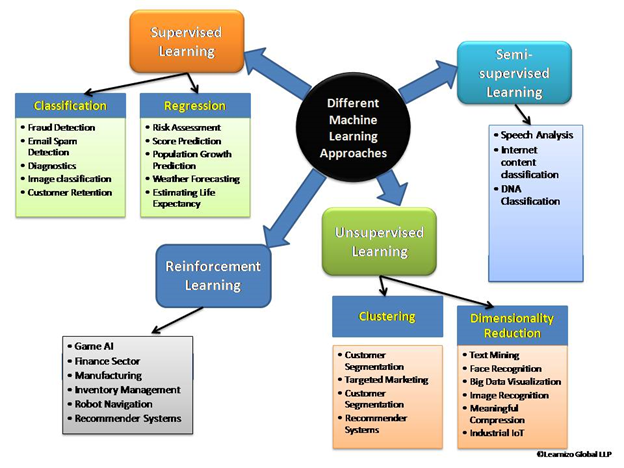
Supervised Learning
Supervised learning is analogous to training a child to walk. You will hold the child’s hand, show him how to take his foot forward, walk yourself for a demonstration, and so on until the child learns to walk on his own.
Supervised learning is when we teach or train the machine using well-labeled data. Which means some data is already tagged with the correct answer. After that, the machine is provided with a new set of data so that the supervised learning algorithm analyses the training data and produces a correct outcome from labeled data.
Supervised learning can be classified into two categories of algorithms:
Classification: A classification logic is when the output variable is a category, such as “Black” or “White” or “likely” and “not likely”.
Regression: A regression logic is when the output variable is a real value, such as “Currency” or “fraction”. Supervised training models have applicability to a variety of business problems, including fraud detection, recommendation solutions, speech recognition, or risk analysis.
Semi-Supervised Learning
In Semi-Supervised learning, the algorithm is trained upon a combination of labeled and unlabeled data. Typically, this combination will contain a very small amount of labeled data and a very large amount of unlabeled data. The basic procedure involved is that first, the programmer will cluster similar data using an unsupervised learning algorithm and then use the existing labeled data to label the rest of the unlabeled data.
Practical applications of Semi-supervised data learning include speech analysis, internet content classification, DNA sequence classification, etc.
Unsupervised Learning
Unsupervised learning is the training of a machine using information that is neither classified nor labeled and allowing the algorithm to act on that information without guidance. Here the task of the machine is to group unsorted information according to similarities, patterns, and differences without any prior training of data.
It allows the model to work on its own to discover patterns and information that was previously undetected. It mainly deals with unlabelled data. Unsupervised learning is classified into two categories of algorithms:
Clustering: A clustering problem is where the algorithm wants to discover the inherent groupings in the data, such as grouping customers by purchasing behavior.
Dimensionality Reduction: An association rule learning problem is where the algorithm wants to discover rules that describe large portions of data, such as people that buy X also tend to buy Y.
In the case of system monitoring, a machine learning program can learn patterns of bandwidth traffic for the network it’s watching and alert programmers when there are traffic patterns that don’t align with usual network activity which is often a sign of a breach.
Neural networks (a series of smaller programs or algorithms, connected together that work toward solving a particular issue or detecting a certain pattern), are a widely-used setup in unsupervised learning. This process, when done through a neural network, is called Deep Learning.
Reinforcement Learning
Reinforcement learning is about taking suitable action to maximize reward in a particular situation. It is employed by various software and machines to find the best possible behavior or path it should take in a specific situation. Reinforcement learning differs from supervised learning in a way that in supervised learning the training data has the answer key with it so the model is trained with the correct answer itself whereas in reinforcement learning, there is no answer but the reinforcement agent decides what to do to perform the given task. In the absence of a training dataset, it is bound to learn from its experience.
One of the most common applications of reinforcement learning is in robotics or game playing. Take the example of the need to train a robot to navigate a set of stairs. The robot changes its approach to navigating the terrain based on the outcome of its actions. When the robot falls, the data is recalibrated so the steps are navigated differently until the robot is trained by trial and error to understand how to climb stairs. In other words, the robot learns based on a successful sequence of actions. The learning algorithm has to be able to discover an association between the goal of climbing stairs successfully without falling and the sequence of events that lead to the outcome.
Reinforcement learning is also the algorithm that is being used for self-driving cars. In many ways, training a self-driving car is incredibly complex because there are so many potential obstacles. If all the cars on the road were autonomous, trial and error would be easier to overcome. Even with this complex scenario, the algorithm can be optimized overtime to find ways to adapt to the state where actions are rewarded.
We shall discuss more different algorithms and applications of Machine learning in our further articles. Till then stay safe and happy learning with Learnizo Global.